
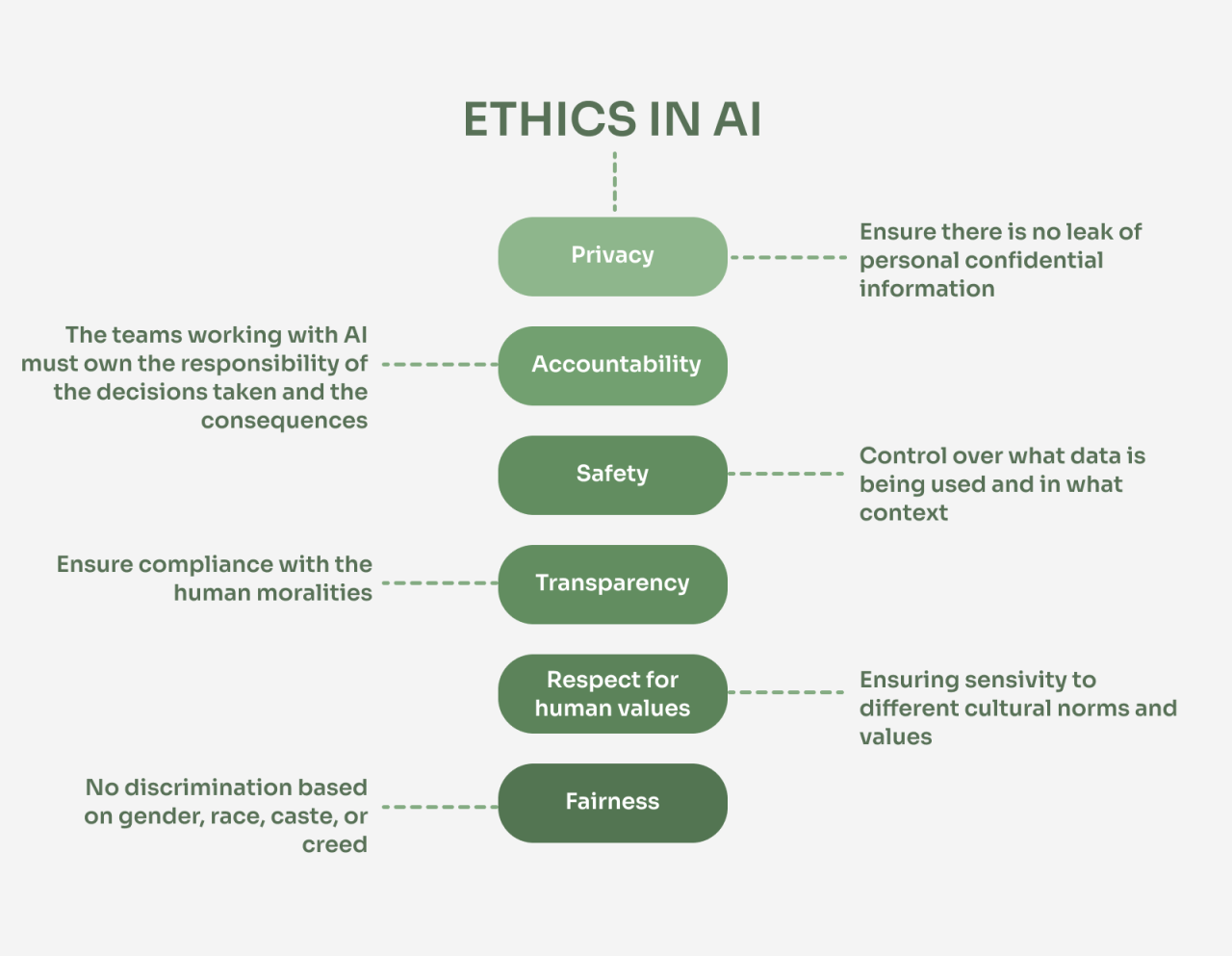
Ethical considerations of using AI with big data in business are paramount in today’s rapidly evolving technological landscape. The power to analyze vast datasets and make predictions using artificial intelligence offers unprecedented opportunities for businesses, but it also presents significant ethical challenges. From ensuring data privacy and mitigating algorithmic bias to establishing accountability and addressing potential job displacement, navigating these ethical complexities is crucial for responsible innovation and sustainable growth.
This exploration delves into the key ethical dilemmas surrounding the intersection of AI, big data, and business practices. We examine the legal and societal implications of deploying AI systems, focusing on the need for transparency, fairness, and user control. Understanding these issues is not just a matter of compliance; it’s fundamental to building trust, fostering ethical business practices, and ensuring a future where AI benefits all of society.
Data Privacy and Security
The intersection of artificial intelligence (AI) and big data presents unprecedented opportunities for businesses, but also significant challenges regarding data privacy and security. The sheer volume and sensitivity of data involved necessitate robust safeguards to comply with regulations and maintain public trust. Failure to address these concerns can lead to substantial legal penalties, reputational damage, and loss of customer confidence.The implications of regulations like the General Data Protection Regulation (GDPR) in Europe and the California Consumer Privacy Act (CCPA) in the United States are profound.
These laws grant individuals significant control over their personal data, demanding transparency and consent for its collection, processing, and use. Businesses leveraging AI and big data must ensure their practices are fully compliant, demonstrating clear and auditable processes for data handling.
GDPR and CCPA Compliance in AI Applications
GDPR and CCPA impose stringent requirements on organizations handling personal data. For AI applications, this translates to a need for demonstrable consent mechanisms, data minimization principles (collecting only necessary data), and robust security measures to prevent unauthorized access or breaches. Companies must also establish clear procedures for data subject access requests, allowing individuals to review and correct their personal information.
Non-compliance can result in substantial fines, impacting profitability and brand reputation. For example, a company using AI to analyze customer purchasing behavior must ensure that it only uses data with explicit consent and that the analysis does not lead to discriminatory outcomes based on protected characteristics. Furthermore, they must be able to demonstrate how the data is used and provide individuals with a mechanism to access and correct this information.
Challenges of Anonymizing and Securing Big Datasets
Anonymizing big datasets used for AI is a complex undertaking. While techniques like data masking and pseudonymization can reduce the risk of re-identification, they are not foolproof. Advances in data linkage and machine learning can potentially re-identify anonymized individuals, especially when combined with publicly available information. Therefore, a multi-layered approach is necessary, combining data anonymization with robust security measures such as encryption, access controls, and intrusion detection systems.
The sheer scale of big data also presents logistical challenges, requiring specialized infrastructure and expertise to manage and secure effectively. For instance, a healthcare provider using AI for diagnostic purposes must ensure patient data is securely stored and accessed only by authorized personnel, adhering to strict anonymization protocols to prevent the leakage of sensitive patient information.
Data Governance Framework for Responsible Data Handling
A comprehensive data governance framework is crucial for ensuring responsible data handling in AI-driven business operations. This framework should include: clearly defined data ownership and accountability; comprehensive data security policies and procedures; a robust data lifecycle management system; regular data quality audits; and a mechanism for handling data breaches and incidents. The framework must be integrated into the organization’s overall risk management strategy and regularly reviewed and updated to adapt to evolving technological and regulatory landscapes.
Effective data governance not only minimizes risks but also fosters trust among stakeholders, contributing to long-term business success. A well-defined data governance framework, including roles and responsibilities, data classification, access control policies, and incident response plans, should be implemented and regularly reviewed to ensure its effectiveness in mitigating risks associated with AI and big data.
Examples of Data Breaches and Consequences
Several high-profile data breaches have highlighted the risks associated with the misuse of AI and big data. For example, the Equifax data breach in 2017, although not directly related to AI, exposed the sensitive personal information of millions of consumers due to vulnerabilities in their systems. This resulted in significant financial losses, legal repercussions, and irreparable damage to their reputation.
Similarly, the misuse of AI-powered facial recognition technology has raised concerns about privacy violations and potential biases. Data breaches stemming from AI applications can have far-reaching consequences, including hefty fines, legal battles, reputational damage, and loss of customer trust. These consequences can significantly impact a company’s financial performance and long-term sustainability. The Cambridge Analytica scandal, while not directly involving a data breach in the traditional sense, demonstrated the potential for misuse of big data and AI to influence elections and manipulate public opinion, underscoring the ethical and societal implications of such technologies.
Algorithmic Bias and Fairness

Algorithmic bias, the systematic and repeatable errors in a computer system that create unfair outcomes, is a significant ethical concern in the application of AI with big data in business. These biases, often stemming from flawed data or design choices, can perpetuate and amplify existing societal inequalities, leading to discriminatory practices and undermining trust in AI systems. Understanding the sources of bias and implementing effective mitigation strategies is crucial for ensuring fairness and ethical AI deployment.
Algorithmic bias manifests in various ways, impacting decision-making across numerous business functions. The consequences can range from subtle inaccuracies to overt discrimination, depending on the context and the severity of the bias. Addressing this requires a multi-faceted approach involving careful data selection, algorithm design, and ongoing monitoring and auditing.
Sources of Bias in Algorithms
Potential sources of bias in algorithms used for business decision-making are multifaceted and often intertwined. These sources can be broadly categorized into data bias, algorithmic design bias, and interaction bias. Data bias arises from skewed or incomplete datasets that reflect existing societal biases. For instance, a hiring algorithm trained on historical data where women are underrepresented in leadership roles might unfairly disadvantage female applicants.
Algorithmic design bias stems from flawed choices made during the algorithm’s development, such as using inappropriate features or relying on simplistic models. Interaction bias refers to how the algorithm interacts with the real world, potentially reinforcing existing inequalities. For example, a loan application algorithm that disproportionately denies loans to individuals from specific zip codes might exacerbate existing economic disparities in those areas.
Methods for Mitigating Algorithmic Bias
Several methods exist for mitigating algorithmic bias, each with its strengths and limitations. Data preprocessing techniques aim to correct imbalances in the training data, such as oversampling underrepresented groups or using techniques like data augmentation. Algorithmic modifications involve designing algorithms that are less susceptible to bias, such as incorporating fairness constraints or using more robust modeling techniques. Post-processing methods adjust the algorithm’s output to mitigate bias after the prediction is made, but this approach can sometimes lead to unintended consequences.
Finally, human-in-the-loop approaches involve incorporating human oversight into the decision-making process to review and correct biased outcomes. The selection of the most appropriate mitigation strategy depends on the specific context and the nature of the bias. A combination of these methods is often necessary for effective bias mitigation.
Examples of Biased Algorithms and Unfair Outcomes
Biased algorithms have resulted in several instances of unfair or discriminatory outcomes in business settings. For example, facial recognition systems have demonstrated higher error rates for individuals with darker skin tones, leading to misidentification and potential miscarriages of justice. Loan application algorithms have been shown to disproportionately deny loans to individuals from specific demographic groups, exacerbating existing economic inequalities.
Hiring algorithms have been criticized for favoring certain demographic groups over others, perpetuating biases in the workplace. These examples highlight the real-world consequences of algorithmic bias and the importance of developing and deploying AI systems responsibly.
Checklist for Auditing AI Algorithms
A comprehensive audit is crucial for ensuring fairness and preventing bias in AI algorithms. This checklist Artikels key steps:
Before initiating an audit, it’s vital to establish clear fairness metrics aligned with the specific context and legal requirements. These metrics should be quantifiable and allow for objective assessment of the algorithm’s performance across different demographic groups.
- Data Assessment: Evaluate the training data for representativeness, biases, and potential sources of error. This includes checking for imbalances in data representation, identifying potentially discriminatory features, and assessing data quality.
- Algorithm Transparency: Document the algorithm’s design, logic, and decision-making process. This facilitates understanding how the algorithm arrives at its predictions and identifying potential biases embedded in the design.
- Performance Evaluation: Assess the algorithm’s performance across different demographic groups, using appropriate fairness metrics such as equal opportunity, demographic parity, and predictive rate parity. Identify disparities in performance and investigate their root causes.
- Mitigation Strategy Implementation: Implement appropriate bias mitigation techniques based on the identified sources of bias and evaluate their effectiveness. Document the changes made to the algorithm and their impact on fairness.
- Ongoing Monitoring: Continuously monitor the algorithm’s performance over time and re-evaluate for bias regularly. Changes in data distributions or shifts in societal biases may require adjustments to the algorithm or its mitigation strategies.
Transparency and Explainability

Transparency in AI systems used for business decisions is paramount for building trust with customers, employees, and regulators. Opaque AI models, where the decision-making process remains hidden, can lead to distrust, hinder accountability, and ultimately damage a company’s reputation. Openness about how AI is used allows for scrutiny, identification of potential biases, and fosters a more responsible approach to AI implementation.The inherent complexity of many AI algorithms, particularly deep learning models, presents significant challenges to achieving transparency and explainability.
These models often involve millions of parameters and intricate interactions, making it difficult to understand precisely why a specific prediction or decision was made. This “black box” nature of some AI systems makes it hard for stakeholders – including business leaders, data scientists, and even the individuals affected by the AI’s decisions – to assess the validity and fairness of the results.
Challenges in Achieving Algorithmic Transparency
Understanding the internal workings of complex AI models is a major hurdle. For example, a deep neural network might identify a pattern in data that leads to a specific outcome, but the network’s internal representation of that pattern might be impossible for a human to interpret directly. Furthermore, the sheer volume of data used to train these models can make it difficult to trace the influence of individual data points on the final prediction.
This lack of interpretability can lead to difficulties in debugging errors, identifying biases, and ensuring compliance with regulations. Addressing these challenges requires a multi-faceted approach combining technical solutions and changes in business practices.
Techniques for Explaining AI Model Predictions, Ethical considerations of using AI with big data in business
Several techniques aim to make AI model predictions more understandable. These techniques can be broadly categorized as model-agnostic or model-specific. Model-agnostic methods can be applied to any model, regardless of its internal structure. Model-specific methods, conversely, leverage the internal workings of a particular model type to provide explanations.
- LIME (Local Interpretable Model-agnostic Explanations): LIME approximates the behavior of a complex model locally around a specific prediction by training a simpler, more interpretable model (like a linear regression) on a small subset of data points near that prediction. This simpler model provides explanations for the original model’s prediction in that specific instance.
- SHAP (SHapley Additive exPlanations): SHAP values quantify the contribution of each feature to a prediction by using game theory concepts. It provides a consistent and efficient way to explain predictions by assigning each feature a value representing its impact on the final outcome. SHAP values can be used to understand which features are most important for a given prediction and how they interact.
- Decision Trees and Rule-based Systems: These models are inherently more interpretable than complex neural networks. Decision trees explicitly represent the decision-making process through a tree-like structure, showing the path taken to arrive at a specific prediction. Rule-based systems express predictions using a set of “if-then” rules, making the logic behind the predictions clear and understandable.
Designing AI Systems for Explainability
Designing an AI system with transparency in mind begins in the initial stages of development. Careful consideration should be given to the choice of algorithms, data selection and preprocessing, and the overall system architecture. The use of inherently interpretable models, like decision trees or rule-based systems, should be prioritized whenever feasible. Where more complex models are necessary, incorporating explainability techniques like LIME or SHAP is crucial.Furthermore, the system should be designed to provide clear and concise explanations of its decisions to both technical and non-technical users.
This may involve creating user-friendly interfaces that visualize the explanations and present them in a way that is easy to understand. Regular audits and evaluations of the AI system are also essential to monitor its performance, identify potential biases, and ensure that the explanations remain accurate and reliable. For example, a loan application system using an AI model could display the key factors contributing to the approval or rejection of an application, helping both the applicant and the loan officer understand the decision-making process.
This promotes transparency and allows for potential challenges to be addressed effectively.
Accountability and Responsibility
The increasing reliance on AI systems in business operations presents significant challenges regarding accountability and responsibility. Determining who is liable when an AI system makes an incorrect decision, causes harm, or violates regulations is a complex issue with far-reaching legal and ethical implications. This section explores the challenges of assigning accountability, the legal ramifications of AI-driven errors, and potential mechanisms for establishing clear lines of responsibility.The challenge of assigning accountability for AI decisions stems from the inherent complexity of these systems.
Unlike human decision-makers, AI operates based on algorithms and vast datasets, making it difficult to pinpoint a single source of responsibility. Is it the developers who created the algorithm? The data scientists who curated the training data? The business executives who deployed the system? Or the AI itself?
This ambiguity creates a legal and ethical grey area, hindering effective oversight and redress for potential harms.
Challenges in Assigning Accountability for AI Decisions
The distributed nature of AI development and deployment complicates accountability. Consider a self-driving car accident: Is the manufacturer liable for faulty software? The owner for improper maintenance? The developers of the mapping data for inaccuracies? Or the AI itself for making a fatal decision?
Establishing clear lines of responsibility requires a multi-faceted approach, involving a careful examination of the entire AI lifecycle, from design and development to deployment and maintenance. Legal frameworks must adapt to address this distributed responsibility, possibly incorporating concepts of shared liability or proportionate responsibility depending on the contribution of each party to the incident.
Legal and Ethical Implications of AI-Driven Errors
AI-driven errors or malfunctions can have significant legal and ethical consequences. These consequences range from financial losses and reputational damage to physical harm and even fatalities. For example, a biased loan-approval algorithm could discriminate against certain demographic groups, leading to legal action for unfair lending practices. Similarly, a faulty medical diagnosis system could lead to misdiagnosis and harm to patients, resulting in medical malpractice lawsuits.
The lack of transparency and explainability in many AI systems further complicates legal proceedings, making it challenging to determine the cause of errors and assign liability. Existing legal frameworks often struggle to address these novel challenges, necessitating the development of new regulations and legal precedents.
Mechanisms for Establishing Accountability in AI-Driven Business Processes
Several mechanisms can help establish accountability in AI-driven business processes. These include rigorous testing and validation of AI systems before deployment, implementing robust monitoring and auditing procedures, establishing clear lines of responsibility within organizations, and fostering a culture of ethical AI development and deployment. Furthermore, the use of explainable AI (XAI) techniques can enhance transparency and provide insights into the decision-making processes of AI systems, making it easier to identify and rectify errors.
The development of standardized auditing protocols specific to AI systems is also crucial. This could involve regular assessments of algorithms for bias, accuracy, and adherence to ethical guidelines. Finally, independent oversight bodies could play a significant role in ensuring accountability and promoting responsible AI practices.
Framework for Determining Liability in Cases Involving AI-Related Harm
A framework for determining liability in cases involving AI-related harm should consider several factors. These factors include the level of autonomy of the AI system, the extent of human oversight, the foreseeability of harm, the contribution of various actors (developers, deployers, users), and the severity of the harm caused. A proportionate liability model, where responsibility is distributed among different actors based on their contribution to the harm, may be more appropriate than a strict liability model.
This framework would need to be adaptable to the rapidly evolving nature of AI technology and its applications. Furthermore, the legal system should focus on establishing clear standards for AI safety and security, including requirements for testing, validation, and ongoing monitoring. This proactive approach would minimize the risk of AI-related harm and facilitate the determination of liability when incidents occur.
Job Displacement and Economic Impact: Ethical Considerations Of Using AI With Big Data In Business

The integration of artificial intelligence (AI) and big data into business operations presents a significant challenge: the potential for widespread job displacement across various sectors. While AI promises increased efficiency and productivity, it also raises concerns about the economic consequences for workers whose jobs become automated. Understanding this impact and developing effective mitigation strategies are crucial for ensuring a just and equitable transition to an AI-driven economy.AI and big data are already automating tasks across numerous industries, from manufacturing and transportation to customer service and data entry.
Routine, repetitive jobs are particularly vulnerable. For example, automated systems are replacing human workers in assembly lines, warehouses, and call centers. The resulting job losses can lead to increased unemployment, wage stagnation, and heightened income inequality, potentially destabilizing communities and creating social unrest. The scale of this displacement is a subject of ongoing debate, with varying predictions depending on the pace of technological advancement and the adaptability of the workforce.
However, the potential for significant disruption is undeniable.
Strategies for Mitigating Negative Economic Impacts
Addressing the negative economic consequences of AI-driven automation requires a multi-pronged approach. This includes proactive measures to reskill and upskill the workforce, creating new job opportunities in emerging AI-related fields, and implementing social safety nets to support those displaced by automation. Government policies, industry collaborations, and individual initiatives all play a vital role in this transition. For example, investing in education and training programs that equip workers with the skills needed for the jobs of the future is paramount.
Furthermore, exploring alternative economic models, such as universal basic income, could provide a safety net for those unable to find alternative employment.
Examples of Successful Retraining and Upskilling Programs
Several successful programs demonstrate the effectiveness of proactive retraining and upskilling initiatives. For instance, Germany’s “Industry 4.0” strategy focuses on investing in education and training to prepare workers for the changing landscape of manufacturing. Similarly, initiatives like the “Tech Talent Pipeline” in the United States aim to bridge the skills gap by providing training in high-demand technology fields.
These programs often involve partnerships between educational institutions, businesses, and government agencies, ensuring that training aligns with the needs of the labor market. Successful programs are characterized by their focus on practical skills, individualized learning pathways, and ongoing support for participants.
A Plan for Ensuring a Just Transition to an AI-Driven Economy
A just transition to an AI-driven economy requires a comprehensive plan encompassing several key elements. This plan should prioritize: (1) Investing heavily in education and training programs tailored to the skills required in an AI-driven workforce; (2) Creating incentives for businesses to invest in retraining their employees, perhaps through tax credits or subsidies; (3) Strengthening social safety nets, such as unemployment benefits and social assistance programs, to support workers during periods of transition; (4) Exploring alternative economic models, such as universal basic income, to mitigate the potential for widespread income inequality; (5) Promoting lifelong learning to ensure that workers can adapt to the constantly evolving demands of the job market; and (6) Engaging in open and transparent dialogue among stakeholders, including government, industry, labor unions, and educational institutions, to ensure that the transition is fair and equitable for all.
This multifaceted approach is essential to harness the benefits of AI while minimizing its potential negative impacts on the workforce.
Environmental Impact of AI and Big Data
The burgeoning field of artificial intelligence, particularly when coupled with the vast datasets required for its training and operation, presents a significant environmental challenge. The energy consumption associated with these processes, coupled with the environmental footprint of data storage and processing, necessitates a critical examination of the industry’s sustainability. This section explores the environmental impact of AI and big data, highlighting both the challenges and potential solutions for a more environmentally responsible approach.The energy demands of AI are substantial and rapidly growing.
Training large language models, for instance, can consume millions of kilowatt-hours of electricity, often relying on energy sources with significant carbon emissions. This energy consumption is not limited to the training phase; the ongoing operation and deployment of AI models also contribute significantly to energy use. The scale of these energy demands raises concerns about the carbon footprint of AI and its potential contribution to climate change.
Energy Consumption of AI Model Training and Deployment
Training large AI models requires massive computational power, often utilizing powerful graphics processing units (GPUs) and specialized hardware. The energy consumption during this training phase is particularly high, often exceeding the energy used throughout the entire lifecycle of smaller, less complex models. For example, the training of a large language model like GPT-3 has been estimated to have consumed millions of kilowatt-hours of electricity, resulting in a substantial carbon footprint.
Furthermore, the continuous operation and deployment of these models, involving inference and data processing, contributes to ongoing energy consumption. Minimizing this energy consumption is crucial for mitigating the environmental impact of AI.
Environmental Footprint of Data Storage and Processing
Beyond the energy consumed during model training and deployment, the storage and processing of vast datasets contribute significantly to the environmental impact of AI and big data. Data centers, which house the servers and infrastructure necessary for storing and processing this data, require significant energy to operate, often relying on air conditioning and cooling systems that consume substantial electricity.
The manufacturing and disposal of the hardware used in these data centers also contribute to environmental pollution and resource depletion. Moreover, the increasing volume of data generated and stored necessitates the expansion of data centers, further exacerbating the environmental footprint.
Sustainable Practices for Developing and Using AI in Business
The environmental impact of AI can be mitigated through the adoption of sustainable practices. This includes optimizing model training processes to reduce energy consumption, exploring the use of renewable energy sources to power data centers, and implementing efficient data storage and processing techniques. Businesses can also prioritize the development and deployment of smaller, more efficient AI models that require less energy to train and operate.
Investing in energy-efficient hardware and adopting strategies for data center optimization can significantly reduce the environmental footprint. Furthermore, promoting responsible data management practices, such as data minimization and efficient data storage, can contribute to reducing the overall environmental impact.
Framework for Assessing the Environmental Impact of AI Projects
A comprehensive framework for assessing the environmental impact of AI projects should consider various factors, including the energy consumption of model training and deployment, the environmental footprint of data storage and processing, and the lifecycle impact of the hardware involved. This framework should include methods for quantifying these impacts, such as calculating carbon emissions associated with each stage of the AI lifecycle.
Such a framework can assist businesses in making informed decisions about the development and deployment of AI systems, ensuring that environmental considerations are integrated throughout the project lifecycle. This approach promotes responsible AI development and helps minimize the environmental footprint of this rapidly growing technology.
User Consent and Control
The ethical use of AI with big data necessitates a robust framework for user consent and control. Individuals must be empowered to understand how their data is being used and to exert meaningful influence over its processing. Without such a framework, the potential for misuse and exploitation is significant, undermining trust and potentially leading to legal repercussions. This section explores the importance of informed consent, methods for empowering user control, best practices for communication, and the design of effective data access, correction, and deletion systems.Informed consent for the use of personal data in AI systems is paramount.
It ensures individuals are aware of how their data will be used, the potential implications, and their rights regarding that data. This goes beyond simple checkboxes; it requires clear, concise, and accessible language, avoiding technical jargon that could obscure the meaning for the average user. Obtaining truly informed consent necessitates transparency about the AI system’s purpose, the types of data collected, the methods used for processing that data, and the potential consequences of participation or non-participation.
Methods for Empowering User Data Control
Empowering users requires providing them with practical tools and mechanisms to control their data. This includes readily available and easily understandable mechanisms for opting in or out of data collection, choosing the level of data sharing, and specifying the purposes for which their data can be used. For instance, a user might be able to choose to share only anonymized data for aggregate analysis while withholding personally identifiable information.
Data minimization, the practice of collecting only the minimum amount of data necessary for a specific purpose, is crucial here. Furthermore, providing granular control allows users to specify preferences regarding the use of their data in different AI applications, tailoring their experience and protecting their privacy.
Best Practices for Communicating Data Usage and AI Applications
Effective communication is key to obtaining informed consent and building user trust. Businesses should adopt clear and accessible language in their privacy policies and data usage descriptions, avoiding technical jargon and legalese. Using visual aids, such as infographics or videos, can significantly improve understanding. Regular updates and notifications about changes to data usage policies are essential, ensuring users remain informed.
Providing a dedicated point of contact for users to address their concerns and questions is crucial. Transparency reports, which detail the company’s data usage practices and the impact of AI systems, further enhance trust and accountability. For example, a company might publish a report detailing the accuracy of its AI-driven credit scoring system and its impact on different demographic groups.
System Design for Data Access, Correction, and Deletion
A user-friendly system should be designed to allow individuals to easily access, correct, and delete their personal data. This requires a streamlined interface that avoids complex procedures or bureaucratic hurdles. Users should be able to view all the data collected about them, identify any inaccuracies, and request corrections or deletions without undue delay. The system should incorporate robust security measures to protect user data during access, correction, or deletion processes.
Furthermore, mechanisms should be in place to handle data portability requests, allowing users to easily transfer their data to another service provider. The implementation should adhere to relevant data protection regulations, such as GDPR or CCPA, ensuring compliance and user rights are upheld.
Conclusion
The ethical considerations surrounding the use of AI with big data in business are multifaceted and demand ongoing attention. Successfully navigating these challenges requires a proactive and multi-pronged approach, encompassing robust data governance frameworks, bias mitigation strategies, transparent AI systems, and clear accountability mechanisms. By prioritizing ethical considerations, businesses can harness the transformative power of AI while mitigating potential risks and fostering a future where technology serves humanity’s best interests.
The journey towards responsible AI adoption is an ongoing process requiring constant vigilance, adaptation, and a commitment to ethical principles.