
The role of AI in predictive analytics for big data is rapidly transforming industries. AI algorithms, fueled by the massive datasets now available, are enabling unprecedented levels of predictive accuracy across diverse sectors. This powerful combination allows businesses to anticipate trends, optimize operations, and make more informed decisions, leading to significant competitive advantages. Understanding how AI enhances predictive modeling is crucial for leveraging the full potential of big data.
This exploration delves into the core AI algorithms driving these advancements, examining their strengths, weaknesses, and optimal applications within different big data contexts. We’ll also cover crucial aspects like data preprocessing, feature engineering, model evaluation, deployment strategies, and the ethical considerations inherent in deploying AI-driven predictive systems. Real-world case studies will illustrate the transformative impact of this technology.
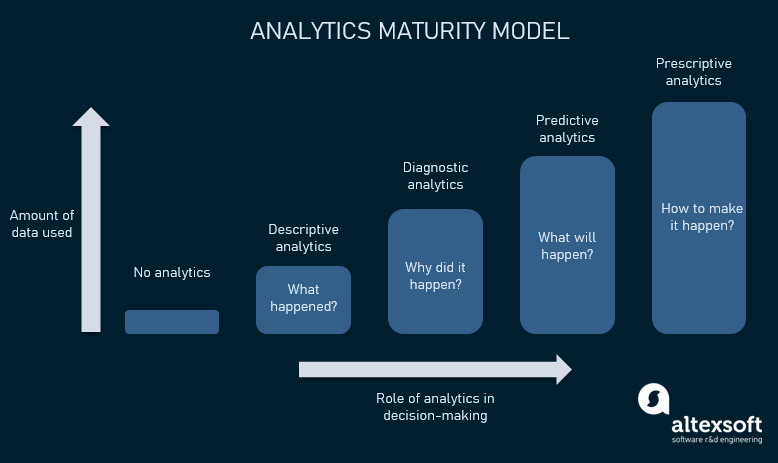
Introduction to AI and Predictive Analytics in Big Data: The Role Of AI In Predictive Analytics For Big Data
Predictive analytics leverages historical data, statistical algorithms, and machine learning techniques to identify the likelihood of future outcomes. Its applications span diverse fields, from predicting customer churn and optimizing marketing campaigns to assessing financial risk and improving healthcare diagnostics. Essentially, it’s about using data to anticipate what might happen next.AI algorithms significantly enhance predictive modeling by automating complex tasks and uncovering intricate patterns within large datasets that traditional methods might miss.
These algorithms, including deep learning and machine learning models, can handle non-linear relationships and high-dimensional data, leading to more accurate and nuanced predictions. Furthermore, AI enables the development of adaptive models that continuously learn and improve their accuracy over time as new data becomes available.Big data, characterized by its volume, velocity, variety, and veracity, provides the fuel for AI-driven predictive analytics.
The sheer quantity of data allows AI algorithms to train on a massive scale, improving model accuracy and generalizability. The diverse nature of big data – encompassing structured, semi-structured, and unstructured data – allows for a more holistic and comprehensive understanding of the factors influencing future outcomes. The velocity of data generation allows for near real-time predictions and adjustments to strategies.
Comparison of Traditional Statistical Methods and AI-Driven Predictive Analytics
The following table compares traditional statistical methods with AI-driven predictive analytics across key characteristics:
| Method | Accuracy | Scalability | Data Requirements |
|---|---|---|---|
| Linear Regression, Logistic Regression | Moderate; assumes linear relationships; prone to overfitting with complex datasets. | Relatively high; easily implemented on large datasets with sufficient computing power. | Structured, clean data with clear relationships between variables. Requires data preprocessing to handle missing values and outliers. |
| Decision Trees, Random Forests | Good; can handle non-linear relationships; less prone to overfitting than linear models. | High; relatively efficient for large datasets. | Can handle both structured and semi-structured data; requires less data preprocessing than linear models. |
| Support Vector Machines (SVMs) | High; effective in high-dimensional spaces; robust to outliers. | Moderate; can be computationally expensive for extremely large datasets. | Requires careful feature engineering and parameter tuning; can handle both structured and semi-structured data. |
| Neural Networks (Deep Learning) | High; can capture complex, non-linear relationships; excellent for image, text, and time-series data. | High; requires significant computing power but can be highly scalable with distributed computing. | Can handle large volumes of structured, semi-structured, and unstructured data; requires substantial data preprocessing and feature engineering for optimal performance. Benefits from massive datasets. |
AI Algorithms for Predictive Analytics

Predictive analytics leverages the power of artificial intelligence (AI) algorithms to extract insights from data and forecast future outcomes. The choice of algorithm significantly impacts the accuracy, efficiency, and interpretability of the predictive model. Understanding the strengths and weaknesses of various AI algorithms is crucial for effective deployment in big data scenarios.
Different AI algorithms excel in specific situations. Machine learning (ML) algorithms, for instance, are well-suited for tasks where labeled data is readily available, while deep learning (DL) excels in processing unstructured data and identifying complex patterns. The selection process often involves considering factors such as data size, data type, desired accuracy, and computational resources. This section will delve into specific algorithms and their applications.
Linear Regression in Predictive Analytics
Linear regression is a fundamental supervised learning algorithm used to model the relationship between a dependent variable and one or more independent variables. It assumes a linear relationship between these variables, predicting the outcome based on a calculated linear equation. This algorithm is computationally efficient and easily interpretable, making it suitable for scenarios with relatively small datasets and clear linear relationships.
For example, predicting sales based on advertising spend often employs linear regression due to its simplicity and ease of understanding the relationship between variables. However, its assumption of linearity limits its effectiveness when dealing with complex, non-linear relationships.
Random Forests for Predictive Modeling
Random forests are ensemble learning methods that combine multiple decision trees to improve predictive accuracy and robustness. They handle both numerical and categorical data effectively and are less prone to overfitting than individual decision trees. Their ability to handle high-dimensional data makes them well-suited for big data scenarios where numerous features are involved. For instance, predicting customer credit risk, considering numerous financial and demographic factors, often benefits from the power and resilience of random forests.
The drawback is their lower interpretability compared to linear regression; understanding the contribution of each variable can be more challenging.
Neural Networks for Complex Predictive Tasks
Neural networks, a core component of deep learning, are powerful algorithms capable of modeling highly complex, non-linear relationships within data. Their ability to learn intricate patterns from large, unstructured datasets makes them ideal for applications like image recognition, natural language processing, and time series forecasting. For instance, predicting customer churn using a combination of transactional data, website activity, and customer service interactions might be effectively modeled using a neural network.
While extremely powerful, neural networks require significant computational resources and can be challenging to train and interpret. The “black box” nature of deep learning models often requires additional techniques to understand their decision-making processes.
Supervised vs. Unsupervised Learning in Predictive Modeling
Supervised learning algorithms, such as linear regression and random forests, require labeled datasets where the outcome variable is known. This allows the algorithm to learn the relationship between input features and the target variable, enabling accurate predictions on unseen data. In contrast, unsupervised learning algorithms, such as clustering and dimensionality reduction, work with unlabeled data, aiming to discover hidden patterns and structures.
While supervised learning is primarily used for predictive modeling, unsupervised learning can be valuable for exploratory data analysis and feature engineering, improving the performance of subsequent supervised learning models.
Predicting Customer Churn with Different AI Algorithms
Consider a telecommunications company aiming to predict customer churn. They possess a large dataset containing customer demographics, usage patterns, billing information, and customer service interactions.
A linear regression model could be initially employed to assess the relationship between basic variables like monthly bill amount and churn probability. However, this model might overlook more nuanced factors. A random forest model could then be trained to incorporate more features, providing a more accurate prediction. Finally, a deep learning model could be used to analyze unstructured data such as customer service transcripts and social media posts, capturing subtle indicators of dissatisfaction that might otherwise be missed.
By comparing the performance of these different algorithms, the company can choose the most effective approach for minimizing customer churn.
Data Preprocessing and Feature Engineering for AI-Driven Predictions
Effective predictive modeling with AI relies heavily on the quality and relevance of the data used. Raw data is rarely suitable for direct input into AI algorithms; it often contains inconsistencies, missing values, and irrelevant features that can hinder model accuracy and performance. Data preprocessing and feature engineering are crucial steps that transform raw data into a format suitable for building robust and accurate predictive models.
These processes significantly impact the overall effectiveness of AI-driven predictions.Data preprocessing involves cleaning and transforming the data to improve its quality and consistency. This includes handling missing values, identifying and addressing outliers, and transforming data types to ensure compatibility with chosen AI algorithms. Feature engineering, on the other hand, focuses on creating new features from existing ones or transforming existing features to enhance the predictive power of the model.
This process involves selecting the most relevant features and discarding irrelevant or redundant ones. Both preprocessing and feature engineering are iterative processes that often require experimentation and refinement.
Handling Missing Values in Big Datasets
Missing data is a common issue in big datasets. Ignoring missing values can lead to biased and inaccurate models. Several techniques exist to handle them, depending on the nature and extent of the missing data. Simple imputation methods, such as replacing missing values with the mean, median, or mode of the respective feature, are often used for numerical data.
More sophisticated methods include k-Nearest Neighbors imputation, which uses the values of similar data points to estimate missing values, and multiple imputation, which generates multiple plausible imputed datasets to account for uncertainty. For categorical data, frequent category imputation or model-based imputation can be employed. The choice of method depends on the characteristics of the data and the desired level of accuracy.
For example, in a dataset of customer transactions, missing values in the ‘purchase amount’ could be imputed using the mean purchase amount for customers with similar demographics.
Outlier Detection and Treatment
Outliers are data points that significantly deviate from the rest of the data. They can disproportionately influence the training of AI models, leading to poor generalization and inaccurate predictions. Detection methods include box plots, scatter plots, and statistical measures like the z-score. Once identified, outliers can be handled through various techniques. These include removal, transformation (e.g., logarithmic transformation to reduce the impact of extreme values), or winsorization (capping values at a certain percentile).
The choice of technique depends on the context and the potential impact of the outliers on the model. For instance, in fraud detection, outliers might represent fraudulent transactions and should not be removed without careful consideration.
Feature Engineering Strategies
Feature engineering is the process of creating new features from existing ones to improve the predictive power of the model. This involves selecting the most relevant features and transforming them to enhance their usefulness. Effective strategies vary depending on the data type.
Feature Engineering for Numerical Data
For numerical data, techniques such as scaling (standardization or normalization), creating interaction terms (combining two or more features), and binning (discretizing continuous variables) are common. For example, in a real estate prediction model, creating a new feature representing the ratio of living area to lot size could improve prediction accuracy.
Feature Engineering for Categorical Data
Categorical data requires different approaches. One-hot encoding converts categorical variables into numerical representations suitable for AI algorithms. Label encoding assigns numerical values to categories, but this can introduce an artificial order which may not be appropriate. For example, in a customer churn prediction model, one-hot encoding can be used to represent different customer segments.
Feature Engineering for Textual Data
Textual data needs to be transformed into numerical representations before it can be used in predictive models. Techniques such as TF-IDF (Term Frequency-Inverse Document Frequency) and word embeddings (Word2Vec, GloVe) are commonly used to convert text into numerical vectors that capture semantic meaning. For example, in sentiment analysis, TF-IDF can be used to represent the importance of words in a customer review.
Model Evaluation and Deployment
Building and training a predictive model is only half the battle. The true value lies in effectively evaluating its performance and seamlessly integrating it into a real-world application. This section details the crucial steps involved in model evaluation and deployment, ensuring the AI-powered predictive analytics system delivers accurate and reliable results.Model evaluation involves rigorously assessing the model’s predictive capabilities using various metrics and techniques to ensure it meets the desired performance standards.
Deployment, on the other hand, focuses on integrating the trained model into a production environment where it can process new data and generate predictions in real-time or near real-time, depending on the application’s requirements.
Key Metrics for Evaluating Predictive Models
Evaluating the performance of AI-based predictive models requires a comprehensive approach, utilizing multiple metrics to gain a holistic understanding of its strengths and weaknesses. Commonly used metrics provide different perspectives on the model’s accuracy and reliability. Choosing the most relevant metrics depends heavily on the specific business problem and the associated costs of false positives and false negatives.
- Accuracy: Represents the overall correctness of the model’s predictions, calculated as the ratio of correctly classified instances to the total number of instances. For example, an accuracy of 90% means the model correctly predicted the outcome in 90 out of 100 cases.
- Precision: Measures the proportion of correctly predicted positive instances among all instances predicted as positive. It answers the question: “Of all the instances predicted as positive, what percentage was actually positive?” High precision is crucial when the cost of false positives is high.
- Recall (Sensitivity): Measures the proportion of correctly predicted positive instances among all actual positive instances. It answers the question: “Of all the actual positive instances, what percentage did the model correctly identify?” High recall is crucial when the cost of false negatives is high.
- F1-score: The harmonic mean of precision and recall, providing a balanced measure of the model’s performance. It is particularly useful when dealing with imbalanced datasets where the classes are not equally represented.
Model Selection and Hyperparameter Tuning
Selecting the optimal model and fine-tuning its hyperparameters are critical steps in achieving high predictive accuracy. Model selection involves comparing different algorithms (e.g., linear regression, logistic regression, support vector machines, random forests, neural networks) based on their performance on a validation set. Hyperparameter tuning involves optimizing the model’s internal parameters (e.g., learning rate, number of trees in a random forest) to improve its performance.Techniques like grid search, random search, and Bayesian optimization are commonly employed for hyperparameter tuning.
Grid search systematically explores a predefined set of hyperparameter values, while random search randomly samples from the hyperparameter space. Bayesian optimization uses a probabilistic model to guide the search for optimal hyperparameters, often leading to faster convergence. Cross-validation is often used to evaluate the model’s performance across different subsets of the data, providing a more robust estimate of its generalization ability.
Deploying a Trained Predictive Model
Deploying a trained model involves integrating it into a real-world application to make predictions on new, unseen data. This process involves several key steps, from selecting an appropriate deployment platform to monitoring the model’s performance in the production environment. Successful deployment requires careful consideration of factors such as scalability, maintainability, and security.
Step-by-Step Guide for Cloud-Based Model Deployment
Deploying a predictive model using a cloud-based platform like AWS SageMaker, Google Cloud AI Platform, or Azure Machine Learning offers scalability, flexibility, and cost-effectiveness. A typical deployment process involves these steps:
- Model Packaging: Prepare the trained model and its dependencies for deployment. This might involve creating a Docker container to ensure consistent execution across different environments.
- Platform Setup: Configure the chosen cloud platform, setting up the necessary infrastructure (e.g., compute instances, storage) for model deployment.
- Model Deployment: Upload the packaged model to the cloud platform and deploy it as a web service or API endpoint.
- Testing and Validation: Thoroughly test the deployed model using a representative sample of new data to ensure its accuracy and reliability in the production environment.
- Monitoring and Maintenance: Continuously monitor the model’s performance and retrain or update it as needed to maintain its accuracy over time. This includes tracking key metrics and addressing any performance degradation.
Ethical Considerations and Challenges

The application of AI in predictive analytics, while offering immense potential, necessitates a thorough examination of its ethical implications. The inherent complexities of AI algorithms, coupled with the sensitivity of data used in predictive modeling, raise concerns about bias, fairness, privacy, and security. Addressing these ethical challenges is crucial for responsible AI development and deployment, ensuring that these powerful technologies are used for the benefit of society.AI-driven predictive models are not immune to biases present in the data they are trained on.
These biases can perpetuate and even amplify existing societal inequalities, leading to unfair or discriminatory outcomes. For example, a loan application algorithm trained on historical data reflecting existing lending biases might unfairly deny loans to applicants from certain demographic groups.
Bias in AI-Driven Predictive Models and Mitigation Strategies
Algorithmic bias arises from skewed data reflecting historical prejudices or societal imbalances. This bias can manifest in various ways, leading to discriminatory outcomes. For instance, a facial recognition system trained primarily on images of light-skinned individuals may perform poorly on individuals with darker skin tones. Mitigation strategies involve careful data curation, employing techniques like data augmentation to increase representation of underrepresented groups, and using fairness-aware algorithms that explicitly address bias during model training.
Regular audits and independent evaluations of models are also critical to detect and correct biases. Techniques like adversarial debiasing and re-weighting samples can help to mitigate bias during the training process.
Ethical Implications in Sensitive Areas
The use of AI for prediction in sensitive areas like healthcare and finance carries significant ethical weight. In healthcare, AI algorithms predicting disease risk or treatment outcomes must be transparent and accountable, ensuring patient privacy and avoiding potentially harmful biases. For example, an AI system predicting patient readmission rates should not disproportionately target specific demographic groups. Similarly, in finance, AI-driven credit scoring models must avoid discriminatory practices, ensuring fairness and equal opportunities.
Robust regulatory frameworks and ethical guidelines are essential to navigate these complexities and ensure responsible AI deployment. Consider the potential for an AI system to incorrectly predict a high risk of a heart attack in a specific demographic group, leading to unnecessary and potentially harmful interventions.
Data Privacy and Security Challenges
AI-based predictive analytics relies heavily on vast amounts of data, raising concerns about privacy and security. The collection, storage, and processing of sensitive personal information necessitate robust security measures to prevent data breaches and unauthorized access. Compliance with data protection regulations, such as GDPR and CCPA, is paramount. Furthermore, the use of anonymization and differential privacy techniques can help to protect individual identities while still allowing for valuable insights.
A data breach involving sensitive health or financial information could have devastating consequences for individuals and erode public trust in AI systems. Implementing robust encryption, access control, and data minimization practices is crucial for mitigating these risks.
Best Practices for Responsible AI Development and Deployment
Responsible AI development and deployment requires a multi-faceted approach. It’s essential to establish clear ethical guidelines and standards, prioritize transparency and explainability in AI models, and ensure accountability for AI-driven decisions.
- Prioritize Fairness and Equity: Actively mitigate bias in data and algorithms to ensure fair and equitable outcomes for all.
- Ensure Transparency and Explainability: Develop models that are easily understood and interpretable, allowing for scrutiny and accountability.
- Protect Privacy and Security: Implement robust security measures to protect sensitive data and comply with relevant regulations.
- Promote Human Oversight and Control: Maintain human oversight in the development and deployment of AI systems to prevent unintended consequences.
- Foster Collaboration and Engagement: Engage with stakeholders, including ethicists, policymakers, and the public, to address ethical concerns.
- Conduct Regular Audits and Evaluations: Regularly assess the performance and ethical implications of AI systems to identify and correct potential issues.
Case Studies and Real-World Applications

AI-powered predictive analytics are transforming industries by enabling data-driven decision-making and improving business outcomes. This section presents several case studies illustrating the successful application of AI in predictive analytics across various sectors, highlighting both the benefits and limitations encountered. The examples showcase the diverse ways AI is enhancing efficiency, profitability, and customer experience.
The integration of AI and predictive analytics is not without its challenges. Factors such as data quality, model interpretability, and ethical considerations play a crucial role in the successful implementation and deployment of these systems. However, the potential for improved accuracy, speed, and automation far outweighs these challenges in many applications.
Examples of AI in Predictive Analytics Across Industries, The role of AI in predictive analytics for big data
The following table summarizes several successful applications of AI in predictive analytics, demonstrating the diverse range of benefits and challenges across various industries.
| Industry | Application | Benefits | Challenges |
|---|---|---|---|
| Finance | Fraud detection | Reduced fraud losses, improved customer experience through faster transaction processing, enhanced security measures. For example, a major credit card company reported a 50% reduction in fraudulent transactions after implementing an AI-powered fraud detection system. | Maintaining model accuracy in the face of evolving fraud techniques, ensuring data privacy and compliance with regulations. Balancing the need for high accuracy with the potential for false positives, which can negatively impact legitimate customers. |
| Healthcare | Predictive diagnosis of diseases | Early detection and intervention leading to improved patient outcomes, personalized treatment plans based on individual risk profiles, optimized resource allocation. A study showed that AI-powered diagnostic tools improved the accuracy of cancer detection by 15%. | Data privacy and security concerns, ensuring model fairness and avoiding bias in diagnosis, addressing the “black box” nature of some AI models, requiring explainability for medical professionals. Need for extensive validation and regulatory approval before widespread adoption. |
| Marketing | Customer churn prediction | Proactive retention strategies targeting at-risk customers, improved customer lifetime value, optimized marketing campaigns, reduced customer acquisition costs. A telecommunications company saw a 20% reduction in churn after implementing an AI-driven churn prediction model. | Maintaining data quality and accuracy, ensuring ethical use of customer data, addressing potential biases in the prediction models, adapting to evolving customer behavior. The challenge of interpreting complex model outputs and translating them into actionable marketing strategies. |
| Retail | Supply chain optimization | Reduced inventory costs, improved forecasting accuracy, optimized logistics and delivery, enhanced customer satisfaction through better product availability. A large retailer reported a 10% reduction in inventory holding costs after implementing an AI-powered supply chain optimization system. | The need for high-quality and real-time data from various sources, dealing with unexpected disruptions (e.g., natural disasters), ensuring the system is adaptable to changing market conditions and consumer demand. Integrating the AI system with existing legacy systems can present significant technical challenges. |
Outcome Summary
In conclusion, the integration of AI into predictive analytics for big data represents a paradigm shift in decision-making across numerous fields. While challenges remain, particularly concerning ethical implications and data privacy, the potential benefits—from improved risk management to personalized customer experiences—are undeniable. As AI algorithms continue to evolve and data volumes expand, the power of AI-driven predictive analytics will only continue to grow, shaping the future of business and beyond.